Prediction Of Return
Dingyi Lai / August 2022
Business Setting
A substential part of products purchased online by customers are returned especially in the case of free return shipping. Given the fierce online competition among online retailers, it is important to predict the potential return behaviour so as to take an extra step, for instance, restrict payment options or display additional marketing communication.
When a customer is about to purchase an item, which is likely to be returned, the shop is planning to show a warning message. Pre-tests suggest that the warning message leads approx. 50% of customers to cancel their purchase. In case of a return, the shop calculates with shipping-related costs of 3 EUR plus 10% of the item value in loss of resale value. Thus, the cost-matrix could be written as the following:
| Tables | Actual_Keep(0) | Actual_Return(1) |
|---|---|---|
| predicted_Keep(0) | C(k,K) = 0 | C(k,R) = 0.5·5·(3+0.1·v) |
| predicted_Return(1) | C(r,K) = 0.5·v | C(r,R) = 0 |
Note that in the dataset, a returned item is denoted as the positive class, and v in the cost-matrix denotes the price of the returned item.
Therefore, besides to predict the return rate as accurately as possible, this model is built to minimize the expected costs, put differently, to maximize the revenue of the online retailer as well.
Blueprint Design
It is unrealistic to form a pipeline for data processing once for all. A reasonable way to regulate pipeline systematically is to define potentially adjustable parameters and fragmentary helper functions. Throughout EDA (Exploratory Data Analysis) and different result after all, a relatively optimal pipeline could be wrapped into one preprocess_df function. An additional function transform_columns is to reduce memory consumption for machine. Codes without accessing to details are presented in this repo
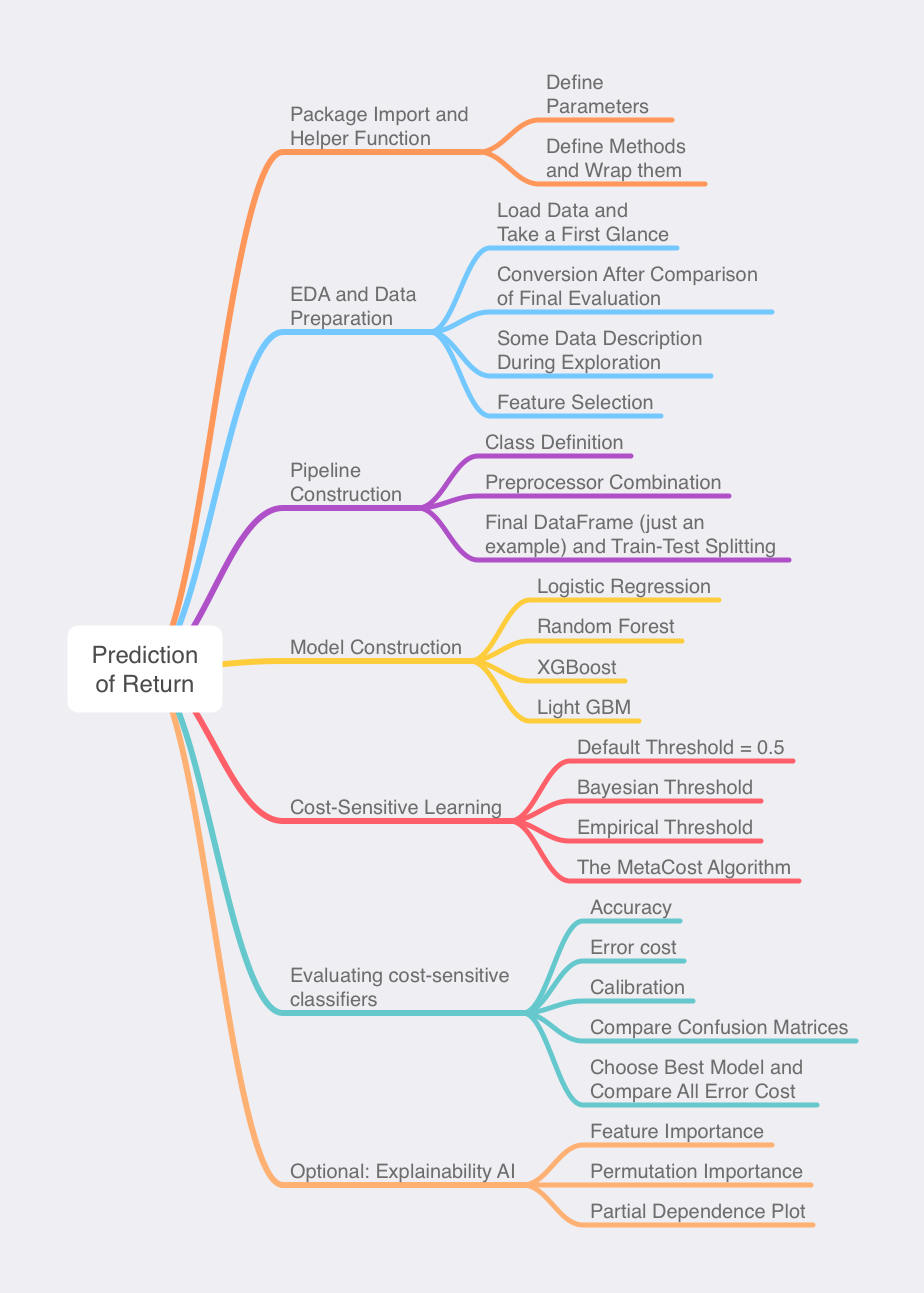
Package Import and Helper Function
Define Parameters
Encounter noisy features, truncation and imputation are worth considering. Note that there are several options for imputation, such as ‘median’, ‘most_frequent’, ‘constant’ ‘mean’…
Define Methods and Wrap them
Scrutinize date features, where there is missing, mark them as a new category. Find out potential reason why outlier or mistake exist. Valuable information could hide inside. Otherwise, consider to remove outliers. As for categorical features, grouping and correcting potential misspelling is neccessary. Adding counting result as frequency is another good move. Let’s move to numerical feature. Truncating it or not, which could be indexed by our parameters above, deserves examination.
EDA and Data Preparation
Load Data and Take a First Glance
Query some properties of the data such as dimensionality, number of cases and information regarding each feature.
Conversion After Comparison of Final Evaluation
Change data type to reduce memory consumption, which could speed up model building.
Note that for categorical features, there are mainly two convenient ways to rearrange them: dummy encoding, WoE (Weight-of-Evidence) transformation. Always remember it is significant to keep test data and train data clearily separable. Therefore, the estimation of WoE score could not be accomplished in this part, since it requires the information of cases with the same category level after all conversions. Low-dimensionalities data is suitable converted by dummy encoding. Unlike WoE encoding, it does not need further constrained information but only the categorical features themselves.
Some Data Description During Exploration
- General information and slicing
- Count, cross table
- (Stack) Count plot, barplot and violin plot
- Correlation and heatmap
- Categorical feature distribution and woebin_plot
- Numericfal feature distribution, boxplot and histogram
Feature Selection
High correlation is an indicator that using both of these features will most likely not be benefitial to the model, as the features carry the same information. Besides, a filter function based on information value (IV: This value will help us understand if the variable is useful in our prediction at all) is applied. Compare IV and Fisher scores among all variables. 0.02 is commonly used as a threshold for IV.
Pipeline Construction
Class Definition
Define ColumnSelector, DropColumns and WoETransformer for preprocession.
Weight of evidence encoding or WoE can be used to check if a variable has predictive power and can replace categories with that predictive power. Note that the WoE transformtion could also applied to a continuous variable after binning that variable. The benefits of this include the ability to combine bins with similar WoE values and create more monotonic relationships which are easy to model. The drawbacks are possible loss of information and lack of ability to find correlation between variables. There is also an alternative way to calculate WoE and handle missing WoE.
Preprocessor Combinition
Combine via FeatureUnion.
Final DataFrame and Train-Test Splitting
Split data into training and testing dataset
Model Construction
I chose to test 4 different models: Logistic Regression, XGBoost, Random Forest and Light GBM.
For each one of them, I will perform the following tasks:
- Define parameter grid and pipeline
- Perform GridSearchCV to find the best parameters
- fine tune the parameters of model
- Fit data on the best performing model
- Plot ROC curve on both training and test data
- showing the performance of a classification model at all classification thresholds
- Plot confusion matrix
- a table that is used to define the performance of a classification algorithm
- Feature coefficients
- find out most predictable features (also as a single chapter)
- Calculate gini
- calculates the amount of probability of a specific feature that is classified incorrectly when selected randomly. Usually, the higher the gini, the better
- Calculate stability of the model
- perform GridSearchCv with different splits to ensure the performance of the model
- Calculate F1 Score
- a measure of a test’s accuracy
- Calculate Brier Score
- a strictly proper score function or strictly proper scoring rule that measures the accuracy of probabilistic predictions
- Model explanation
- only for chosen models
Logistic Regression
Logistic regression estimates the probability of an event occurring, such as return or didn’t return, based on a given dataset of independent variables. Since the outcome is a probability, the dependent variable is bounded between 0 and 1.
Logistic Regression predicts the test data with accuracy of 69%. The accuracy is the same for the train and test data, which is an indicator, that the model performs well and does not overfit.
Random Forest
The random forest (RF) algorithm is a powerful, robust, and easy to use algorithm for regression and classification. RF ground on two principles, random subspace and bagging. Multiple trees are grown from bootstrapped samples drawn from the training set with replacement. Many trees (i.e. a forest) are grown (sometimes their maximum depth is also specified) and all trees provide a prediction for cases of the test data. Each tree’s vote generally has the same weight. Up until here, the algorithm is equivalent to bagging. It differs in the growing of individual tress. Specifically, when growing a tree, the next best split is not determined by searching a splitting criteria among all features. Only a subset of features is drawn at random (random subspace) and the best split is determined among this random subset.
In this model, a change in the value of item_size could change the output of the model a lot! A change in item_price would also have an effect on the output as well as user_id_frequency. The rest of the models have low coefficient values.
XGBoost
Gradient boosting is one specific form of boosting (using residuals recursively to increase accuracy). This process begins with an initial simple prediction, which is often the mean of the target variable. Next, the algorithm iteratively goes through every feature and determines which feature will best reduce this error with a single split. This is essentially a single level tree, or stump. This stump is then chosen and added to the ensemble. Next, residuals are calculated once again and the process continues for as many iterations as deemed necessary.
Extreme Gradient Boosting was explicitly designed for highly scalable gradient boosting.
Here we have a slightly higher accuracy score. Again we can say that there is no overfitting here, as the train and test AUC are very close. According to feature importance, delivery_date_1994, item_price and item_size play a huge role for this model.
Light GBM
In order to speed up the tuning process, I had to abandon my beloved XGBoost algorithm, and embrace LightGBM. It is precisely introduced in Wikipedia that “LightGBM, short for Light Gradient Boosting Machine, is a free and open source distributed gradient boosting framework for machine learning originally developed by Microsoft” (Cite from https://en.wikipedia.org/wiki/LightGBM). Compared to XGBoost that we have learned in class, LightGBM uses histogram based algorithm, i.e. it buckets continuous feature values into discrete bins, speeding up the training process, so that it has faster training speed and higher efficiency, lower memory usage; Also, it produces much more complex tress by following leaf wise split approach rather than a level-wise approach, which leads to better accuracy than any other boosting algorithm (Cite from https://www.analyticsvidhya.com/blog/2017/06/which-algorithm-takes-the-crown-light-gbm-vs-xgboost/).
In a nutshell, LightGBM is fast and comparable to XGBoost.
My sequence of tuning the model is :
-
using default parameters and set learning_rate = 0.1 ,num_iterations = 200 (relatively high)
-
Adjust
max_depthandnum_leavesto determine the size and complexity of the tree
parameters = {
'max_depth': [4,6,8],
'num_leaves': [20,30,40],
}
- Adjust
min_data_in_leafandmin_sum_hessian_in_leafto prevent overfitting of the trees
parameters = {
‘min_child_samples’: [18,19,20,21,22],
‘min_child_weight’:[ [0.001,0.002]
}
- Adjust
feature_fractionto prevent overfitting
parameters = {
'feature_fraction': [0.6, 0.8, 1],
}
- Adjust
bagging_fractionandbagging_freqsimultaneously.
bagging_fraction is equivalent to subsample, which can make bagging run faster, and can also reduce overfitting. The default bagging_freq is 0, which means the frequency of bagging, 0 means no bagging is used, and k means bagging is performed once every k iterations.
parameters = {
'bagging_fraction': [0.8,0.9,1],
'bagging_freq': [0,1,2,3],
}
- Adjust lambda_L1 (
reg_alpha) and lambda_L2 (reg_lambda) to reduce overfitting
parameters = {
'reg_alpha': [0.003,0.005,0.007],
'reg_lambda': [4,5,6],
}
- Adjust
cat_smoothto reduce noise
parameters = {
'cat_smooth': [0,10,20],
}
- Reduce
learning_rateslightly and adjustnum_iterations
Summary
In this pretty table we can compare the scores of 5 different measurements on the models.
With the highest value in all measurements but the Brier score, where it has the lowest value, Light GBM is the ‘winner’. This model gives the most accurate predictions for the test data. It is safe to say that all models perform relatively good.
Parameter evaluation
Based in the results in the table above, the following parameters were chosen, as they resulted in the highest values.
- truncate_item_price = True
- truncate_delivery_days = False
- truncate_age = False
- cut_age = True
- numeric_imputer_strategy = ‘median’
- numeric_standard_scaler_mean = True
Cost-Sensitive Learning
Because we are not only eager to have a high accuracy of prediction, a low expected cost is also desired. Even though Light GBM performed best in terms of predicting unseen data, I would still want to keep all models to evaluate which one would result in the lowest cost. In cost-sensitive learning I derived cost-minimal classification cut-off based on Bayes Decision Theory. Then I used empirical thresholding to tune the cut-off. After that, I tried the MetaCost algorithm to improve the result. To check the calibration, I used calibration curve. Other evaluation metrics include accuracy and error cost. All things considered, I will choose the final model and cost-sensitive learning method.
Default Threshold = 0.5
When result is > 0.5, then the obs is classified as return, otherwise is as not return. A cost matrix is thus derived and a
Bayesian Threshold
Next, I calculate average costs for the items with the assumption that all of them were classified as False Positives (FP) or as False Negatives (FN). Then I will use these values to create the cost matrix.
Empirical Threshold
Then, I will perform Empirical Thresholding to see if there is another threshold, that would result in lower costs for my models. Here, the goal is not to find an auc-maximizing cutoff, but a cost-minimizing one. Therefore, a cross-validation approach is performed with an average over all cutoffs with the lowest error-cost for each fold.
The MetaCost Algorithm
Lastly, I will try the MetaCost algorithm. In the first step of the algorithm, I apply the minimal bayes cutoff and use it to label our data. With the probability predictions for the test set for this model, I apply the Bayes minimal cutoff to it. Then this vector is used as the new y_train. Next, another model is trained on the data including the new labels then predict the output of the test set. As the first model, I use Logistic Regression. For the case of Logistic Regression itself, I chose to use XGB as the trained model to label the data.
Evaluating cost-sensitive classifiers
Accuracy
Error cost
Calibration
To implement cutoff-based approaches for cost-sensitivity, we need well calibrated probability predictions. Well calibrated probability predictions are ones for which the output of model.predict_proba() is such that among the samples to which it gave a prediction value close to 0.8, approximately 80% actually belong to the positive class
Compare confusion matrices
Choose Best Model and Compare All Error Cost
Optional: Explainability AI
Feature Importance
Impurity-based feature importance for tree-based models provides with a measure capturing the total contribution of the feature age toward impurity reduction in the tree. Repeating the process for every feature in the data set, we can compare how valuable each feature has been.
Although, the results from the impurity-based feature importance analysis is quite reasonable, we don’t know the direction a feature affect predictions. Also, since Strobl et al. (2007) has demonstrated how the impurity-based approach is biased toward categorical variables with many levels, the contribution of all WoE values based on high-dimensional features is spurious.
Permutation Importance
It is a learner-agnostic way to judge the relevance of features and to produce an ordinal feature ranking.
Partial Dependence Plot
It depicts the marginal effect of a feature on model predictions.
Conclusion
After all of the exhausting data cleaning(missing values, outliers, wrong data), feature transformation(datetime, WoE in pipeline, dummy, scalling in pipeline), descriptive analysis(cross table, count plot, violin plot, correlation plot), model training (random forest and lightgbm), feature selection(IV, Fisher scores), model tunning (GridSearchCV), cost-sensitive analysis(cost-minimal cutoff, empirical approach, MetaCost approach, calibration curve), model evaluation(SMOTE, AUC, return-to-keep ratio, Accuracy, Sensitivity, Specificity, Recall, Precision, G-mean and F1-measure), feature importance analysis (Impurity-based feature importance, Permutation-based feature importance, partial dependence plot), the computation of actual cost based on test data and of expected cost based on unknown data, I got my result. Although through feature importance analysis, I know that my features are not satisfying and perfect, the whole process for business analysis and data science is still badly thought-provoking and educational. The most important and meaningful lessons I learnt in this assignment is: Always seperate testing data and training data clearily especially in the process of feature transformations. Pipeline is really a good idea to achieve them.
Reference
-
Hanley, J. A., & McNeil, B. J. (1983). A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology, 148(3), 839–843. https://doi.org/10.1148/radiology.148.3.6878708
-
Pedro Domingos. 1999. MetaCost: a general method for making classifiers cost-sensitive. In Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining (KDD ‘99). Association for Computing Machinery, New York, NY, USA, 155–164. DOI:https://doi.org/10.1145/312129.312220
-
Strobl, C., Boulesteix, AL., Zeileis, A. et al. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinformatics 8, 25 (2007). https://doi.org/10.1186/1471-2105-8-25
-
Geoff Pleiss, Manish Raghavan, Felix Wu, Jon Kleinberg, and Kilian Q. Weinberger. 2017. On fairness and calibration. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 5684–5693.
-
https://github.com/Dingyi-Lai/bads/blob/master/tutorials