Uplift Modeling
Dingyi Lai / August 2022
Introduction
Uplift models are popular methods to support marketing decision-making problems. With uplifts models, marketing analysts are able to estimate the causal effect of marketing treatment on consumer behavior. Consider the example of an e-mail campaign that aims to send digital discount codes to customers as an incentive for the customers to buy, and thus, to e.g. drive sales revenues. The causal effect of the price discount is the treatment effect. It quantifies the change in customer’s buying probability due to the marketing activity (i.e. the price discount). Estimating the causal effect of a marketing activity is crucial to for instance evaluate the true impact of a marketing campaign.
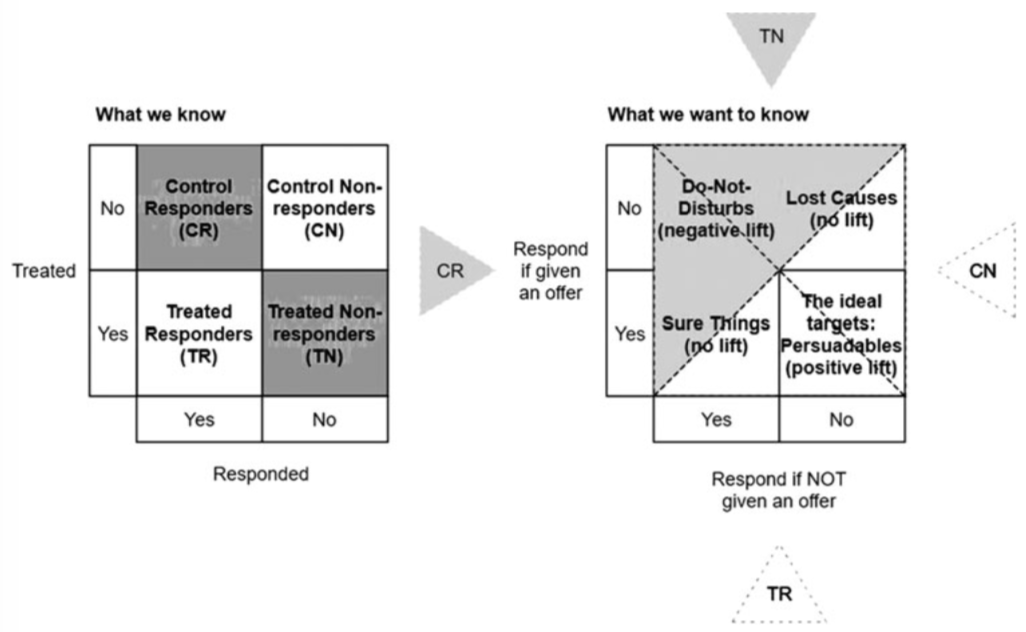
It is important to carefully decide which customers should receive treatments. As shown in the adapted Figure 1 by Devriendt et al. (2018), customers can be assigned into four targeting groups based on whether a customer responds when treated or not treated: sure things, lost causes, persuadables, and do-not-disturbs. Uplift models should predict the persuadables. Based on data from which we can observe whether a customer was targeted and whether the customer responded, we want to get the information of those customers who responded because we targeted (i.e. treated) them with our marketing activity (Kane et al., 2014). As discussed by Lai (2006) and Kane et al. (2014), customers can be grouped further into four categories: Control responders, treatment nonresponders, control nonresponders and treatment responders. The latter two are labeled as positive lifts because they contain all persuadables (positive targets, i.e. customers who respond only if they are targeted), whereas the first two are considered as negative lifts. Thus, uplift models must identify those customers who have no initial intention to buy but can be influenced to buy because we target them, which essentially implies causality. With this we can avoid for example negative profit by targeting the wrong customers. Devriendt et al. (2018) give a comprehensive overview of the state-of-the-art in uplift modeling.
The uplift (Devriendt et al., 2018) is considered as the impact of the treatment or respectively the difference in behavior of customers due to the marketing activity (e.g. discount, retention program, newsletter). The uplift \(U(x_i)\) is defined as the probability of a customer to respond if treated minus the probability of the customer to respond when not treated:
\begin{equation} U(x_i): = p(Y_i | X_i, T_i = 1) - p(Y_i | X_i, T_i = 0) , \end{equation}
where \(T\) denotes the treatment variable, \(Y\) the target , \(X\) the features and \(p\) the probability estimated by a model.
There exists different types of the treatment effects. Here we just briefly mention the parameters that are of our interests.
The Individual Treatment Effect (ITE):
\begin{equation} \tau^{ITE} = \tau_i = Y_i(1) - Y_i(0) \end{equation}
The Conditional Average Treatment Effect (CATE), which is the individual or group-level effect of the treatment: \begin{equation} \tau^{CATE} = \tau(x) = E(Y_i(1) - Y_i(0) | X_i = x_i) \end{equation}
The Average Treatment Effect (ATE), which is the overall effect of the treatment of the customers:
\begin{equation} \tau^{ATE} = E(\tau(x)) = E(Y_i(1) - Y_i(0)) \end{equation}
The aim of this notebook is to exploit different methods of neural networks for the estimation of treatment effects in an uplift modeling setting and in a marketing context. For this we use the data of an e-mail marketing campaign provided by Hillstorm (Hillstorm, 2008). The notebook is structured as the following. In the first section we briefly revisit the main concept of uplift modeling, we then give a more comprehensive overview of recent neural network based treatment effect estimation approaches and introduce evaluation metrics. In the next section a descriptive analysis introduces the underlying data set for targeting marketing campaigns. Then we give implementation details on three neural network based methods in an uplift modeling setting, followed by an analysis and evaluation to compare their performances. Lastly, we summarize the results of our project and discuss possible limitations and provide an outlook.
Review of Related Literature
In recent years, more and more researchers are focus on treatment effect estimation. Recent works have also looked into how machine learning method can help to detect treatment effects. But it has been used in this field many years ago. Lo(2002) estimates the uplift in a market experimental dataset, with two estimators, a logistic regression model and a neural network. Shalit et al.(2017) applies an algorithm based on a two-headed outcome-only neural network model estimating individual treatment effect(ITE) to give a generalization-error bound, which is known as TARNet.
In the same year, Louizos et al.(2017) proposes a new model also for estimating ITE, which is based on Variational Autoencoders following the causal structure of inference with proxies. Farrell et al.(2018) uses ReLU as activation function \(\sigma(x)=max(x,0)\) to construct a feedforward neural network. ATE is used for evaluationg the treatment effect. Shi et al.(2019a) introduces DargonNet, which is multi-head lead neural network architecture. It uses representation learning ideas for treatment effect estimation and exploits the sufficiency of the propensity score for estimation adjustment. Further works in recent years have related to deep neural network. Farajtabar et al.(2020) advocates balance regularization of multi-head neural network architectures.
In our paper, we use the following algorithms to train our data: causal network algorithm from Farrell et al.(2018), DragonNet from Shi et al.(2019a) and CEVAE from Louizos et al.(2017). The first two are delicately studied, but for the last one we just dabble to add a new dimension to analyze this problem.
Experimental Design
This section gives an overview of the dataset E-Mail Analytics And Data Mining Challenge by Hillstrom (2008). We do some exploratory data analysis and prepare the dataset.
Exploratory Data Analysis (EDA) & Data Organization
We choose Kevin Hillstrom as our data, which is from E-Mail Analytics And Data Mining Challenge (Hillstrom 2008). The dataset consists of records reflecting customers that last purchased within 12 months.
The relevant codes and dataset are in this repo.
In the data set, we have 64,000 observations in 12 columns, which represents customers’ features, treatment and their responses.
There is no null values. So we could use the data without dealing with missing value. Next step, we would see more details of the data.
Among the 12 columns, there are 3 possible targets.
-
Visit: 1/0 indicator, 1 = Customer visited website in the following two weeks.
-
Conversion: 1/0 indicator, 1 = Customer purchased merchandise in the following two weeks.
-
Spend: Actual dollars spent in the following two weeks.
As a prototype, we firstly choose Conversion as our target y. As for Conversion: on the one hand, it makes more sense than Visit, because it shows customers’s real reaction to treatment, though its response size is smaller than Visit; on the other hand, Conversion is binary variable, it can fit many methods. As for Spend, it shows actual dollars that the customers spent, which is also meaningful to be a target variable. However, some algorithms that we choose cannot be used for continous target. Thus, the only target variable in our paper is Conversion.
Concerning the indicator of treatment, Segment is appropriate. There are three levels:
-
Mens E-Mail
-
Womens E-Mail
-
No E-Mail
Then the regressor may contain the following:
-
Recency: Months since last purchase.
-
History: Actual dollar value spent in the past year.
-
Mens: 1/0 indicator, 1 = customer purchased Mens merchandise in the past year.
-
Womens: 1/0 indicator, 1 = customer purchased Womens merchandise in the past year.
-
Zip_Code: Classifies zip code as Urban, Suburban, or Rural.
-
Newbie: 1/0 indicator, 1 = New customer in the past twelve months.
-
Channel: Describes the channels the customer purchased from in the past year.
History_Segment could be deleted, because its information is covered by History.
Then we will transform the catogorical features into dummies with one-hot-encoding, so that we can better distinguish different groups of catogorical features and more conveniently analyse them, e.g. make a histogram and a heat map. Moreover, with the help of dummy variables, we can use a single regression equation to represent multiple groups. Hence, we do not need to write out separate equation models for each subgroup. Besides, a dummy-coded methods could be used for tackling the nominal variable issues.
We examine sub-groups to check whether there is a meaningful imbalance between the targets.
As the result shows, Conversion is extremely imbalanced. Although we do not apply any specific imbalance methods to deal with that, we combined Mens E-mail and Womens E-mail into one treatment to decrease the imbalance.
Next step is to create some charts, so that we can understand the data better.
Pie Plot
We create a pie plot based on customer’s decision to purchase, in order to see the proportion of different types of customers. In the chart, they are marked by CR (Control Responders), CN(Control Nonresponders), TR(Treatment Responders) and TN(Treatment Nonresponders), which represents their positions in marketing campaign. The value of treatment effect estimation is to adjust the structure of pie plot to reduce the cost, and to improve the efficiency of mailing strategy.
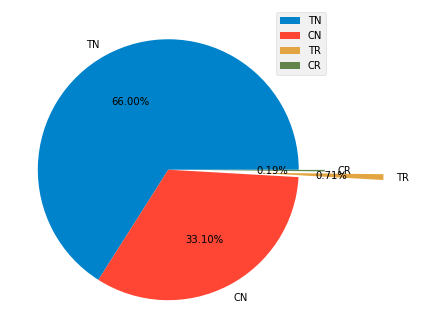
As you can see, 66.00% customers did not buy anything after they received E-mails, which are almost two times larger than the proportion of those customers(CN) who did not receive any E-mail. In the meanwhile, 7.1% customers in treatment group and 1.9% in contol group purchased merchandise.
Histogram
In the aim to see the distributions of all features, we create histograms.
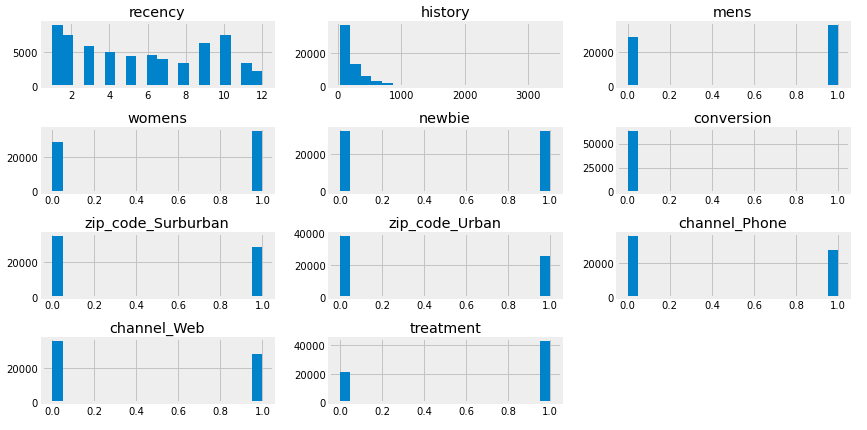
The feature recency has two peaks, one is near 0, the other one is in 10. This means that the new costumers(recency \(\in\) [0,2]) form the largest group among all other groups, followed by the group of customers who have not bought anything for 10 months.
The histogram of history is reasonable: less customers have high spending.
From Newbie it is shown that there are about 50% new costumers in the dataset.
zip_code_Surburban and zip_code_Urban express two opposite areas, so we assume it will have negative correlation with each other which is supported by a heat map shown below.
Heat map
The aim of making a heat map is to check the correlation among these variables.
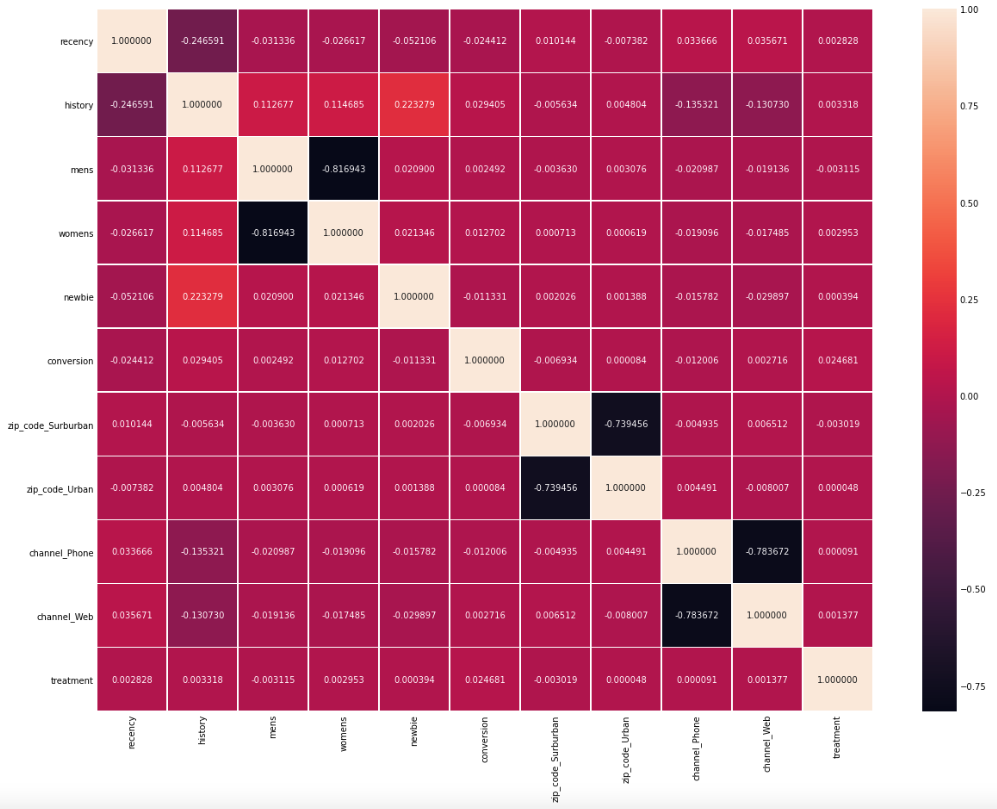
mens and womens are negative correlated, indicating that those who purchased Mens merchandise in the past year and those who bought Womens merchandise in the past year are generally two seperate groups.
It is also easy to understand why the other two groups of variables zip_code_Surburban and zip_code_Urban, channel_Phone and channel_Web are also strongly negative correlated, because they are mutually exclusive.
We need to do data precessing before we apply our methods to them. We transform them into datatype “Float”, to speed up modeling and to save more space. For easier handeling, we separate them into feature matrix X, response Y and treatment T. Moreover, we split them into training set(80%) and test set(20%).
Uplift Model Evaluation Metrics
In this section we briefly explain which metrics we use to evaluate the uplift models.
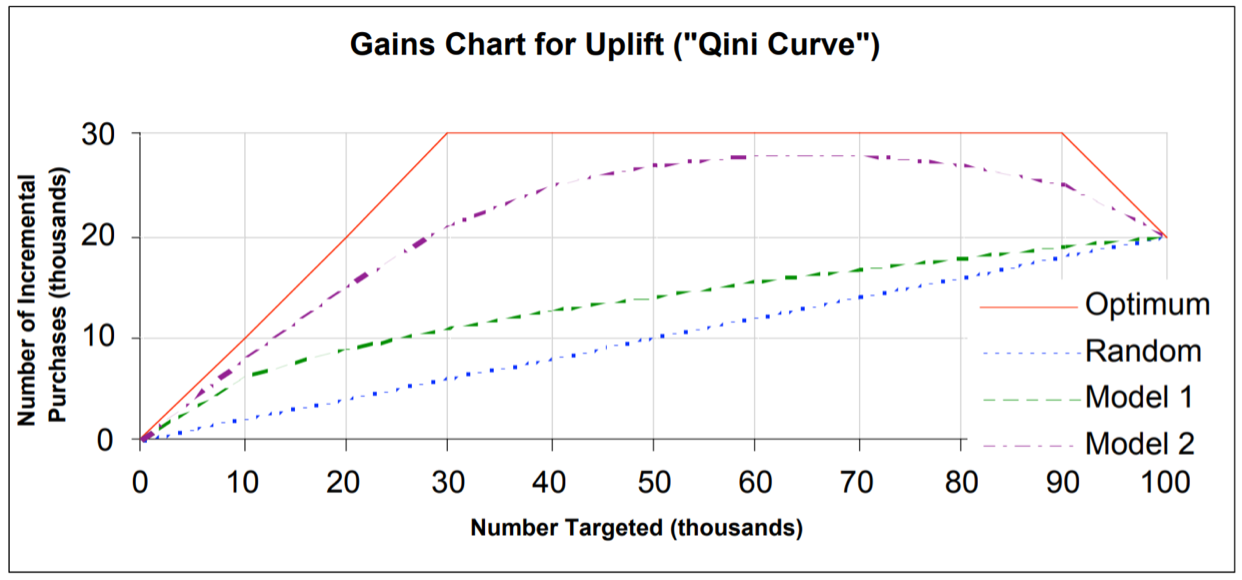
In general the Gini coefficient measures the goodness-of-fit by utilizing gains chart (Devriendt et al., 2018). It is computed by measuring the ratio of the area between the curve of the cumulative lift (accumulation of the responses divided by total amount of responses) and the diagonal line (which is the random targeting) (Figure 5). The Gini coefficient ranges from 0 (i.e. the model performance is not better than random targeting) to +1 (i.e. it represents a perfect model which separates customers clearly into positive and negative class) and to -1 (i.e. worst model performance, where non-purchase is ranked above all purchasers) (Radcliffe, 2007, as cited in Radcliffe and Surry, 2011).
However, the Gini coefficient is not a suitable measurement in an uplift modeling setting, where we have both the treatment and control groups, since it is impossible to simultaneously target and not target one customer and thus, we cannot know how an individual would respond in both groups (Devriendt et al., 2018). Therefore, evaluating uplift models requires specific performances measures to cope with the causal inference problem. We use the Qini coefficient and Qini curve and the AUUC as our evaluation metrics.
The Qini coefficient by Radcliffe and Qini curves generalize the Gini coefficient (Radcliffe 2007, as cited in Devriendt et al., 2018). The evaluation of uplift models lean on gain charts for uplift. Gain charts are built by sorting the main population from best to worst lift performance and partitioning it in segments. The Qini curve (cumulative incremental gains) represents the cumulative difference in response rate between the treatment and control group, where groups of observations instead of individual observations are compared to evaluate the performance. The Qini curve is ranked by the uplift model from high to low uplift. The x-axis represents the proportion of the population targeted and the y-axis the cumulative incremental gains (Figure 5). The Qini coefficient is the area between the Qini curve (i.e. the performance of the uplift model) and the diagonal line (i.e. the random targeting) (Radcliffe and Surry, 2011). Note that higher Qini values corresponds to better performance.
Another metric to evaluate the performance of uplift models is Area Under the Uplift Curve (AUUC) (Rzepakowski & Jaroszewicz, 2010). In comparison to the Qini coefficient measure, the AUUC does not consider the random incremental gains through random targeting (Devriendt et al., 2018). The AUUC calculates the area underneath the uplift curve. We can compare this value to the area under the optimal curve. AUUC measures the cumulative uplift along individuals sorted by the predicted ITE. Higher AUUC score indicates a good model (larger incremental gains).
Methodology
Baseline Models
Theory of Baseline Models
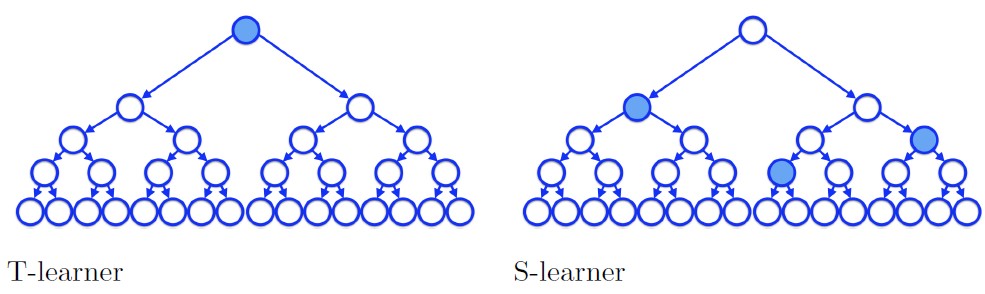
We choose S- and T-learner, two base-learners in meta-algorithms, as our benchmark models for estimating CATE. According to Kuenzel et al.(2019), the T-learner is a tree-based method and includes two tree base learners in it, in order to estimate the two responses from treatment and control groups.
Step 1: Using any supervised machine learning or regression algorithm as a base learner to estimate
\[\mu_0(x)=E[Y(0)|X=x]\] \[\mu_1(x)=E[Y(1)|X=x]\]With the treated observation, we can denote the estimators by \(\hat{\mu_0}(x)\) and \(\hat{\mu_1}(x)\).
Step 2: The T-learner is defined as:
\[\hat{\tau_T}(x)=\hat{\mu_0}(x)-\hat{\mu_1}(x)\]Closely related to the T-learner, S-learner, a “single estimator”, estimates the outcome using all of the features and the treatment indicator, without giving the treatment indicator a special role. The predicted CATE for an individual unit is then the difference between the predicted values when the treatment assignment indicator (\(w\)) is changed from 0 (control) to 1 (treatment), with all other features held fixed. We thus estimate the combined response function,
\[\mu(x,w):=E[Y^{obs}|X=x,\;W=w],\]using any base learner on the entire data set. Also, we denote the estimator as \(\hat{\mu}\). The CATE is,
\[\hat{\tau}_s(x)=\hat{\mu}(x,1)-\hat{\mu}(x,0)\]The difference between S-learner and T-learner is that, in S-learner in which part to split the treatment is decided by the standard squared error loss function, that means the split could be anywhere in the tree. But in T-learner it must be at the very beginning. From the following picture, the difference can be obviously observed. The blue circle is where the split happens.
Implementation of Baseline Models
There exists a python package called causalml (Lee et al., 2021) that contains many different packages for uplift modeling and causal inference methods with machine learning algorithms based on recent research. In this package, XGBRegressor is used for estimating T-learner and S-learner. So we get the average treatment effect of Base learner, whose result is shown below.
Causal Network Algorithm
Theory of Causal Net
Neural networks model the relationships between inputs and outputs via different patterns of hidden layers, the computational units in the hidden layers are called neurons. Farrell et al.(2018) use ReLU as activation function \(\sigma(x) = max(x,0)\) to construct a feedforward neural network.
As the prototype shows (Figure 7), there are U=5 hidden neurons, grouped in a sequence of L=2 layers, which is named the depth of the network. W=18 is denoted as the total number of parameters, with weights=12 and bias=6.
In the paper, they use the average treatment effect(ATE) as their parameter of interest. Empirically, the treatment is being mailed a catalog and the outcome is whether the person is converted. Because we train the model based on the inputs \(X\), in reality the average realized outcome could be interpreted as estimated ATE.
The estimates of the regression functions \(\mu_t(x) = E[Y(t)|X=x], t \in {0,1}\) is used for calculation of conditional average treatment effect (CATE): \(\tau(x) = \mu_1(x)-\mu_0(x)\) Then the optimization function could be fomulated as:
\[\begin{pmatrix} \hat{\mu_0}(x)\\ \hat{\tau}(x) = \hat{\mu_1}(x)-\hat{\mu_0}(x) \\ \end{pmatrix} := \underset{\tilde{\mu_0},\tilde{\tau}}{\operatorname{argmin}}\sum^{n}_{i=1}\frac{1}{2}(y_i-\tilde{\mu_0}(x_i)-\tilde{\tau}(x_i)t_i)^2\]This formular comes directly from the original paper, where \(y_i\) are targets (in our context is convertion), \(x_i\) are features, \(\mu_0(x_i)\) reflects original conversion (0 or 1), and \(\tau(x) = \hat{\mu_1}(x_i)-\hat{\mu_0}(x_i)\) is the CATE of catalog mailing.
Accordingly, we could expect that our ATE should be between 0 and 1. For example, if one customer is originally not converted, then after the mailing strategy, the conversion might be increased, but the conversion target should still be smaller or equal 1. If our target is spend, then the range of “lift” will not have such limitation.
The main difference between T-learner and Causal Net is that the former is based on a two-model approach, which means to seperately develop treatment and control response models to estimate the probability of response; While the latter one is to estimate the response and non-response based on the same model, and to use their estimates to estimate the treatment effect. (Kane, Lo, and Zheng, 2014)
Implementation of Causal Net
From the github repository https://github.com/uber/causalml, we hereby applied a function called causal_net_estimate to build a model for causal inference.
The results and their interpretations from the causal_net_estimate function is as following:
-
tau_predis the estimated conditional average treatment effect -
mu0_predis the estimated target value given x in case of no treatment -
prob_t_predis the estimated propensity scores -
psi_0is the influence function for given x in case of no treatment -
psi_1is the influence function for given x in case of treatment -
history_dictis the dictionary that stores validation and training loss values for CoeffNet -
history_ps_dictis the dictionary that stores validation and training loss values for PropensityScoreNet. If estimate_ps is set to None, history_ps_dict is set to None as well.
If we equip the neural network with only one hidden layer with 60 neurons, and its dropout_rates is 0.5 as a manner of regularization preventing from overfitting. The learning rate is assigned to be 0.0003, the optimization algorithm we choose is “Adam”. Adaptive Moment Estimation (“Adam”) is one of the gradient descent optimization algorithms that computes adaptive learning rates for each parameter, keeping an exponentially decaying average of past gradients (Ruder, 2016). Because our data is sparse, it is reasonable to use “Adam”. The sensitivity analysis afterwards shows that learning rate is not sensitive after a specific thredshold, which might be caused by this adaptive learning-rate method, “Adam”.
Dragonnet
Theory of the Dragonnet
Shi, Blei and Veitch (2019a) introduce a neural network architecture, the Dragonnet, to estimate the treatment effects for observational data. The Dragonnet is a three-headed neural network architecture that provides an end-to-end training to predict the conditional outcomes and the propensity score (Figure 8). The objective of the Dragonnet is to learn a shared representation layer \(Z(X)\) that aims for good prediction of the conditional outcomes \(Q(t,x) = E[ Y | t, x ]\) (input treatment \(T\) and covariates \(X\) to predict the outcome \(Y\)), and also for good prediction of the propensity score \(g(x) = P( T=1| x)\) (input covariates \(X\) to predict the probability of treatment \(T\)). The Dragonnet outputs two heads for the conditional outcomes, denoted as \(Q(1,X)\) if \(t\)=1 and \(Q(0,X)\) if \(t\)=0. Additionally, there is one head for the propensity score \(g(x)\) which is used to enforce a representation that provides good treatment prediction.
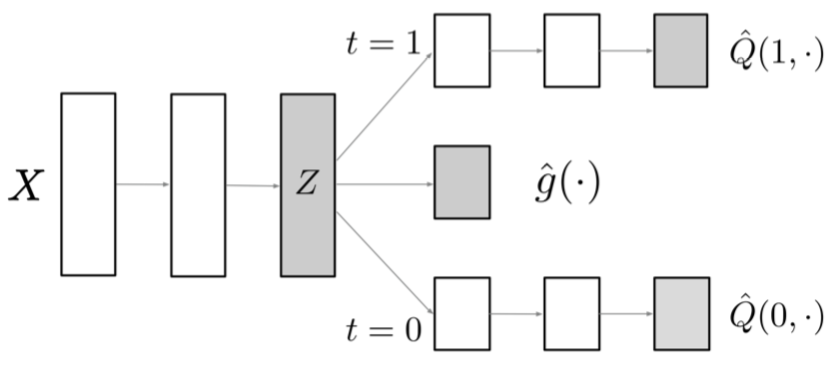
The Dragonnet exploits the sufficiency of the propensity score \(g(x)\) (Shi, Blei and Veitch, 2019a). This is defined as:
\(\tau = E[E[Y|g(X),T=1]-E[Y|g(X),T=0]]\)
if
\(\tau = E[E[Y|X,T=1]-E[Y|X,T=0]]\)
(if the average treatment effect \(\tau\) is identifiable from observational data by adjusting for \(X\)).
So when working with observational data, the theorem of the propensity score states that it is sufficient to adjust only for the information in those features \(X\) that are relevant for predicting the treatment \(T\). The other features are relevant for predicting the outcome \(Y\), but they do not affect the treatment assignment and thus, are irrelevant for the estimation of the causal effect. One way to efficiently filter the relevant features \(X\) in the Dragonnet is to correct for the shared hidden layers (i.e. for example to produce a representation layer \(Z(X)\) and by adding the propensity score as an additional output to discard the irrelevant information and instead focus only on the relevant information in \(X\)). If the propensity score head is removed from the Dragonnet, then the architecture is essentially the TARnet architecture from Shalit et al. (2016) (Shi, Blei and Veitch, 2019a).
Shi, Blei and Veitch (2019a) approach has two stages: At first they fit the model for the conditional outcome \(Q(x)\) and the propensity score \(g(x)\). In the next stage they plug these fitted models \(Q(x)\) and \(g(x)\) into a downstream estimator \(\tau\).
The authors use the estimated average treatment effect with conditional outcome \(\hat{\tau}^{Q}\): \(\hat{\tau}^{Q} = \frac{1}{n} \sum_i[\hat{Q}(1,x_i)-\hat{Q}(0,x_i)]\), where \(\hat{Q}\) is the estimates of the conditional outcome \(Q(t,x) = E[ Y | t, x ]\). This estimator is extended by considering \(\hat{g}\) the estimates of the propensity score \(g(x) = P( T=1| x)\).
To train the model the authors define the objective function as a minimization problem:
\begin{equation} \hat{\theta} = argmin_{\theta} \hat{R}(\theta;X), where \hat{\mathbf{R}}(\theta;X) = \frac{1}{n} \sum_i [(Q^{nn}(t_i,x_i;\theta)-y_i)^2 + \alpha CrossEntropy(g^{nn}(x_i;\theta),t_i)] \end{equation}
and \(\theta\) denotes some parameters of the Dragonnet, \(\hat{Q}^{nn}(t_i, x_i; \theta)\) and \(\hat{g}^{nn}(x_i; \theta)\) are the output heads and \(\alpha \in \mathbb{R}_+\) is a hyperparameter weighting the loss components of the loss function. Based on the fitted outcome model \(\hat{Q}\), the treatment effect with the estimator \(\hat{\tau}^Q\) can be estimated (Shi, Blei and Veitch, 2019a).
Alternatively, the modified objective function, the targeted regularization, can be used for training the neural network (Shi, Blei and Veitch, 2019a). The targeted regularization is based on the non-parametric estimation theory. With this a fitted model with asymptotic properties can be guaranteed if \(\hat{Q}\) and \(\hat{g}\) are consistent estimators for the conditional outcome and propensity scores and if the tuples satisfies the non-parametric estimating equation:
\begin{equation}
0 = \beta \frac{1}{n} \sum \phi (y_i,t_i,x_i,\hat{Q},\hat{g},\hat{\tau})
\end{equation}
The neural network is then trained by minimizing this modified objective function (targeted regularization):
\begin{equation}
\hat{\theta}, \hat{\epsilon} = argmin_{\theta,\epsilon}[\hat{R}(\theta;X) + \beta \frac{1}{n} \sum_i \gamma(y_i,t_i,x_i ; \theta, \epsilon)]
\end{equation}
where \(\beta \in \mathbb{R}_+\) is a hyperparameter , \(\epsilon\) a model parameter and \(\gamma\) a regularization term.
For this the estimator \(\hat{\tau}^{treg}\) is defined as:
\begin{equation} \hat{\tau}^{treg}=\frac{1}{n}\sum_i \hat{Q}^{treg}(1,x_i)-\hat{Q}^{treg}(0,x_i) , where \ \hat{Q}^{treg}=\tilde{Q}(\cdot;\cdot;\hat{\theta};\hat{\epsilon}) \end{equation} Minimizing the targeted regularization term forces (\(\hat{Q}^{treg}\), \(\hat{g}\), \(\hat{\tau}^{treg}\)) to satisfy the non-parametric estimating equation.
Implementation of the Dragonnet
The causalml python package also includes the neural network based algorithms of the relatively new model the Dragonnet, which we use for the implementation procedure of our project. Additionally, Shi, Blei and Veitch provide a GitHub Repository (Shi, Blei and Veitch, 2019b) with their implementation of the Dragonnet on semi-synthetic data for adapting neural networks for the estimation of treatment effects.
As mentioned earlier, we use the conversion variable as our target. We train the Dragonnet over 30 epochs following mostly the default configuration proposed by Shi, Blei and Veitch (2019b). However, we adjust some hyperparameters: the neurons per layer, the ratio and the learning rate. The default setting uses three fully connected layers with 200 units for the shared representation network, we use 190 units. The ratio is set to 0.7 and the learning rate to 0.0006. We apply the targeted regularization (the modified objective function). We also use the default of a combined loss function (the so called dragonnet_loss_binarycross, i.e. the regression loss and binary classification loss) and the L2 regularization (Ridge Regression) to prevent overfitting. The propensity score function \(g(x)\) is implemented as a single linear layer with sigmoid activation function, which forces the representation layer to tightly couple to the estimated propensity scores (Shi, Blei and Veitch, 2019a).
After doing the sensitive analysis (view details in section 5.3) we were able to achieve better performance. Without the sensitive analysis the Dragonnet performs slightly worse than the random targeting. We assume this might be due to the fact that the Dragonnet’s improvements is more significant with smaller data size. Also, the Dragonnet is supposed to predict the outcome from only information relevant to treatment \(T\), and thus, it has worse performance as a predictor for the outcome, but better performance as an estimator (Shi, Blei and Veitch, 2019a).
Here is an overview of the parameters with the default values of the DragonNet function:
- neurons_per_layer=200
- targeted_reg=True (targeted regularization)
- ratio=1.0
- val_split=0.2
- batch_size=64
- epochs=30
- learning_rate=0.001
- reg_l2=0.01 : L2 Loss Function (Ridge Regression) to minimize the error which is the sum of the all the squared differences between the true value and the predicted value.
- loss_func: dragonnet_loss_binarycross is a combination of the regression loss and binary classification loss (binary_crossentropy) of the predicted values
- verbose=True
CEVAE
The Dragonnet as well as the Causal Effect Variational Autoencoder (CEVAE) are based on the TARnet architecture by Shalit et al. (2016). TARnet is a feed forward neural network architecture for causal inference (Shalit et al., 2016). While the Dragonnet extends the TARnet with it’s additional output head for the propensity score, the CEVAE conditions on latent variables instead on observations as in TARnet. In this section we introduce the architecture of CEVAE by Louizos et al. (2017) and our implementation procedure.
Theory of CEVAE
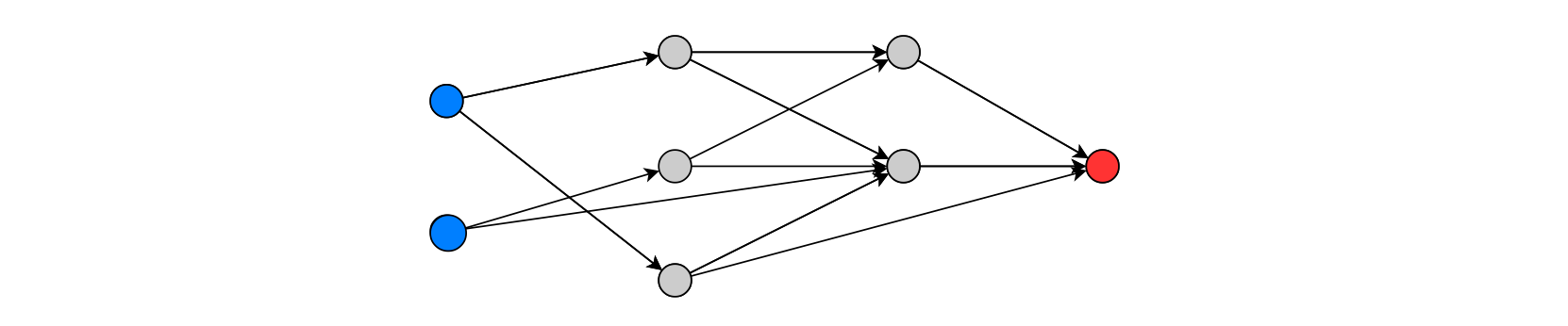
Louizos et al.(2017) propose a new model for estimating ITE, which is based on Variational Autoencoders following the causal structure of inference with proxies. Figure 9 shows a simplified architecture of CEVAE, which is cut from the paper of Louizos et al.(2017).
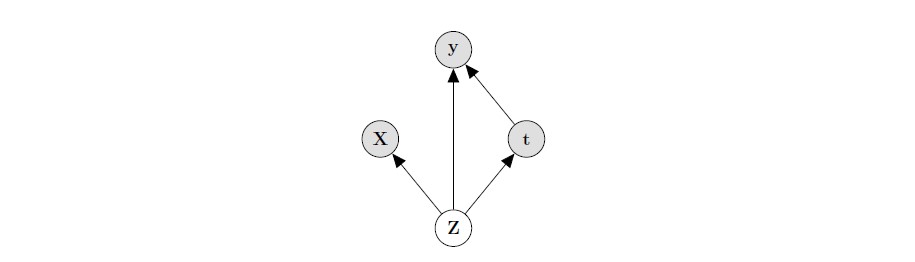
t is a treatment, y is an outcome, Z is an unobserved confounder and X is feature variables which has noisy views on Z.
As this prototype shows, Louizos et al.(2017) assume that there is a latent variable \(Z\), which is an unobserved confounder and has an effect on the outcome \(y\). Furthermore, they assume that the joint distribution \(p(Z;X;t;y)\) of the latent confounders \(Z\) and the observed confounders \(X\) can be approximately recovered from the observations \((X; t; y)\) and \(y\) is independent of \(X\) given \(Z\).
The goal of this paper is to recover the ITE: \(ITE(x) := E[y|X = x; do(t = 1)] - E[y|X = x; do(t = 0)]\) \(ATE := E[ITE(x)]\)
do means using do-calculus rules.
They prove that if \(p (Z;X; t; y)\) can be recovered then the ITE under the causal model in Figure 10 would also be recovered. With the theorem, they obtain \(p(y|X; do(t = 1)) = \int_{Z} p(y|t = 1;Z)\; p(Z|X) dZ\).
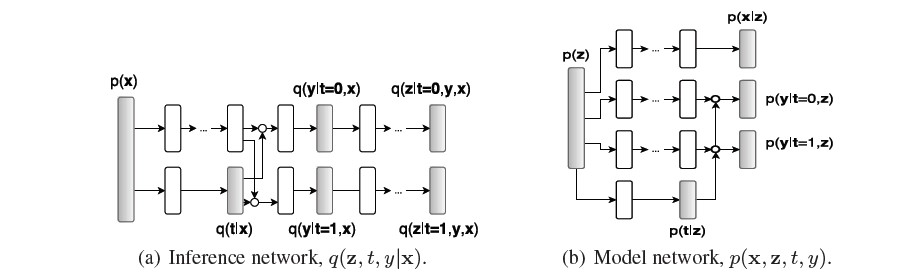
In Figure 10, white nodes mean parametrized neural network transformation, grey nodes mean drawing samples from their distribution and white circles mean switching paths according to the treatment.
This is the architecture of CEVAE, which includes two networks, model network(Figure 7, b) and inference network(Figure 7, a). In model networks, ITE and the distribution over \(Z\) could be recovered. In inference network, samples could be predicted by inferring the distribution over $Z$. While the model network is for training, the inference network is for predicting.
So firstly, they set \(p(z_i)\, =\, \prod_{j=1}^{D_z} N(z_{ij}|0,1)\), so that they can calculate the conditional probability \(p(x_i|z_i)\) and \(p(t_i|z_i)\). It should be mentioned that for a discrete outcome, they use Bernoulli distribution similarly parametrized by a TARnet and Gaussian distribution for a continuous outcome. Thus, \(p(y_i|t_i;z_i) = N(\mu, \sigma^2)\) or \(p(y_i|t_i;z_i) = Bern(\pi)\) would be estimated from neural networks.
So far, the model network has been trained. But how to predict results? In fact, they use the true posterior over \(Z\) depends on \(X\), \(t\) and \(y\), in order to employ the following posterior approximation: \(q(z_i|x_i; t_i; y_i) =\prod_{j=1}^{D_z} N(\mu_j = \bar{\mu}_{ij} ; \sigma^2_j = \bar{\sigma}^2_{ij})\)
Same as before, parameters \(\sigma\) and \(\mu\) will be estimated from neural network. They get the treatment assignment \(t\) from its outcome \(y\) before inferring the distribution over \(Z\) from distributions \(q(t_i|x_i)\) and \(q(y_i|t_i;z_i)\), whose parameters would be trained by networks, too.
In this algorithm, they also mention the variational lower bound, but because of its difficult calculation and limits, we did not use it in our paper.
Implementation of CEVAE
The causalml python package also includes the CEVAE which we install for our implementation. So here we directly input CEVAE model from package causalml.
We need to prepare the dataframe first since the concept of Cevae requires to reorder the columns of dataframe depending on the data type due to the different distribution that they are assigned to, i.e. binary variables with Gausian distribution and continous variables with Bernoulli distribution.
Following we used function cevae for this algorithm. Here are parameters in cevae.
outcome_distis the distribution as one of: “bernoulli” , “exponential”, “laplace”, “normal” and “studentt”.latent_dimis dimension of the latent variable.hidden_dimis dimension of hidden layers of fully connected networks.num_epochsis number of training epochs.num_layersis number of hidden layers in fully connected networksbatch_sizeis batch sizelearning_rateis the final learning rate, which would be learning_rate * learning_rate_decaylearning_rate_decayis learning rate decay over all epochs
It should be mentioned that setting of latent_dim, hidden_dim, num_layers and two learning rate come from Louizos et.al.(2017). Because they got them from another papers and thought that would be the most proper setting, so we did not change them. Besides, we did not do tuning for cevae, the reason is that has taken more than 20 minutes for a circle. If we tune it, it must cost too much time. So we used default setting for unmentioned parameters, num_epochs, num_layers and batch_size.
After setting the basic model, we would fit it and predict.
Tune Parameters
In this section we show the process on how we tune the hyperparameters of our models and show its results.
Since we do not know the suitable architecture for all methodologies, and there is a risk to directly use the default parameters provided by the focal paper of each model, we decide to tune the model empirically. Unfortunately, both GridSearchCV and BayesianOptimization do not meet the need of our models, we have to do some sensitivity analysis and then tune the parameters from scratch.
Rerunning the tuning part is sort of waste of time, because it took quite a long time. we are determined to store the results and present them straightforward. The detailed codes are stored in the file utils.py, which needs to be stored in a local position. The link with the file to our global GitHub repository can be found here: https://github.com/Aubreyldy/APA_M1_data.
Baseline Model Tuning
The AUUC and Qini of T-learner are all insensitive to the tuning. To ensure coherency, the learning rate is set to be 0.0004 above.
Causal Network Tuning
Tuning parameters in Causal Net is way more complicated, because there are several options, and especially for hidden layer size and dropout rate, we can even adjust the number of layers. First we choose the two-layers architecture, observing the trend of results from tuning. The architecture is hidden layer size = [30,i], dropout rate = [0.5,0], i is in range of (10,41).
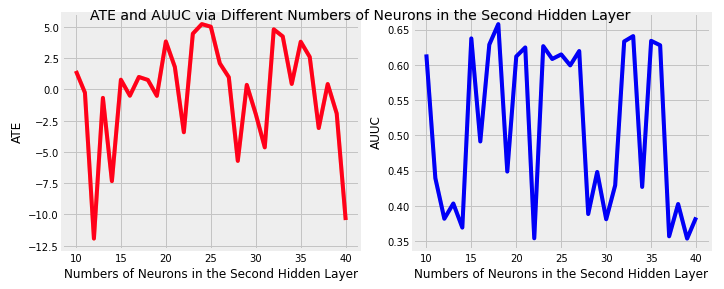
From the two line plot we can see that there are some weird ATEs which are beyond the range of 0 and 1. It might be because the ReLU activation function cannot bound the result into the reasonable range for binary output. But if we select the best AUUC in the experiment, the corresponding ATE is inside the range. In the paper, the reason why they change smooth sigmoid-type activation function to ReLU(rectified linear units) is to overcome optimization hurdles, and they argue that ReLU is for general feedforward achitecture, letting the bound be operational and flexible to yield an optimal rate, while optimizing a deep net with sigmoid-type activation is unstable.
Then we checked the sensitivity of dropout rate.
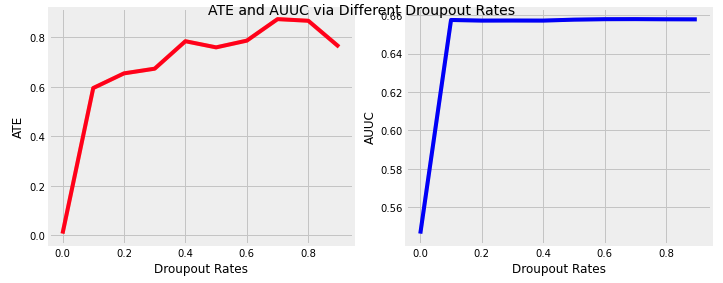
Up to some points, the AUUC is not too sensitive to the increasing of dropout rate any more, compared to the beginning stage.
Next we tried to delete one layer from that, keeping others the same. The result shows that only keeping the first layer would be more possible to give a better result. The architecture for one-layer causal neural net is hidden layer size = [30], dropout rate = [0.5].
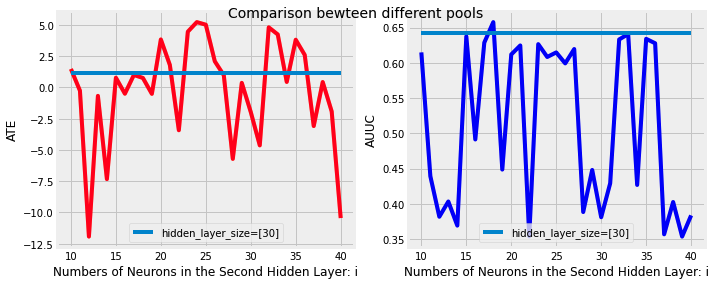
Finally, we tune the one-layer architecture comprehensively empirically.
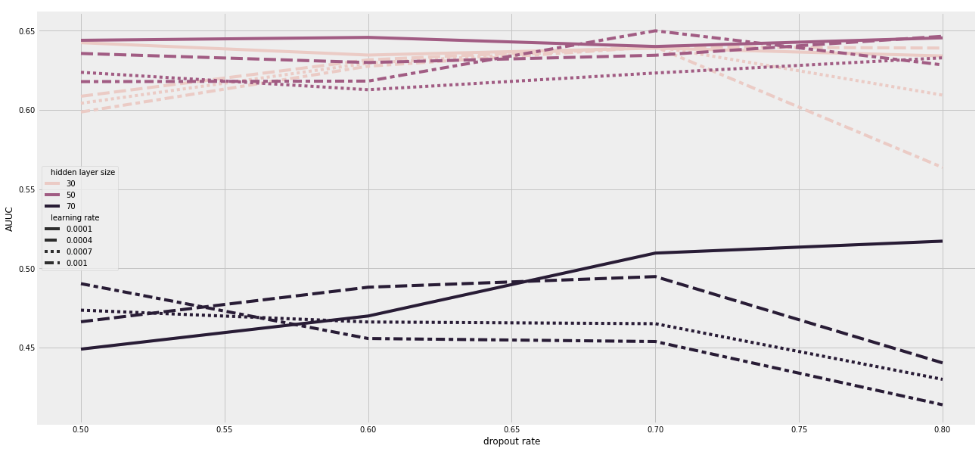
Based on this specific data and parameter setting, when hidden layer size is set to 30 or 50, the AUUC scores are higher than that whose hidden layer size is 70. Expect for this trend, it is difficult to say which learning rate and dropout rate is more suitable. Specific to the pools that we try, the combination of one-layer with 50 hidden layer size, 0.001 learning rate and 0.7 dropout rate is satisfying. This parameter setting has slightly lower AUUC than what we choose to implement Causal net above, therefore, this session is only to show how the tuning could be accomplished.
In conclusion, before implementing directly the treatment estimation methods, it is reasonable to tune the parameter, in case the result is not optimal.
Dragonnet Tuning
There are mainly three parameters that could be tuned: neurons per layer(npl), ratio and learning rate(lr), because these three parameters significantly affect the result.
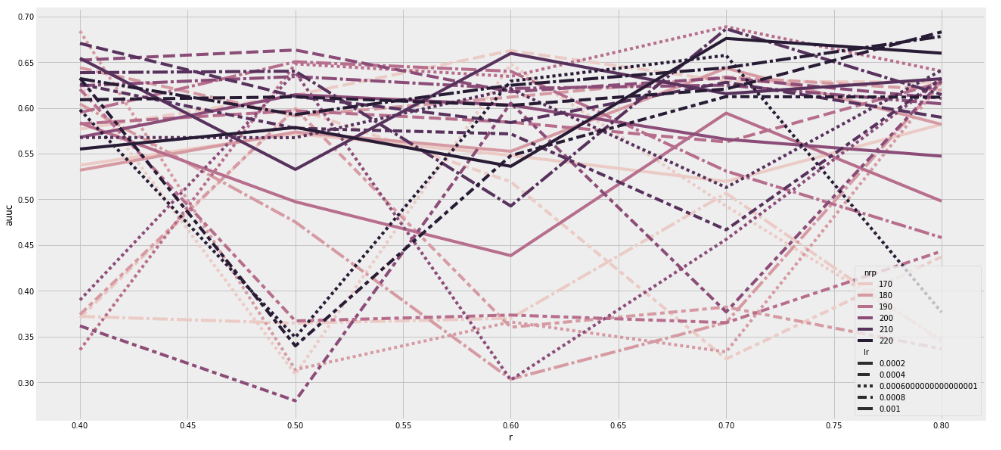
Dragonnet is sensitive to the combination of different parameters, but there is no clear trend. The best pool among them is: npl=190, ratio = 0.7, lr=0.0006.
Empirical Results
In this section, we plot the distribution of CATE as well as the Gain chart and compute the AUUC and Qini scores of our models based on the previous hyperparameters tuning setup.
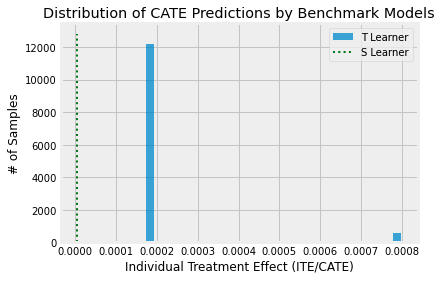
The results of CATE distribution from Benchmark Models are reasonable. Because S-learner does not classify the observation, its result is a line around zero, which shows its ITE(0.000004). The T-learner is Two-Tree estimator, thus its observation is shown in two groups. Obviously, we cannot use the results from baseline models, since they are too simple and just to provide reference results to compare it with our neural network models.
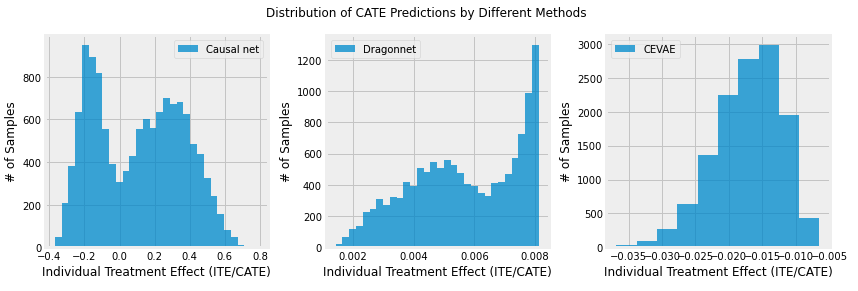
The plots above represent the distribution of ITE/CATE over the sample size of a number of targeted customers. However, the range of ITE/CATE values varies between the different neural network models of the causal net, dragonnet and cevae. Unfortunately, we cannot observe a clear tendency overall all the applied neural network models of customers respond to our treatment from the first glance.
In the result from Causal Net, although the largest group in our potential customers has negative CATE, which means that they might be pushed away from purchasing due to our mailing treatment, the magority of people tend to increase the posibility to buy in our e-mail campaign. Therefore, if we are decision-makers, we would only send e-mails to those customers who have positive CATE and stop distributing advertisement to those customers who have negative CATE.
The results of the Dragonnet shows the distribution of the targeted customers over only a small range, close to the value 0. This indicates that the effect of our treatment variable, i.e. to treat customers with the e-mail campaign in order to gain a conversion, is not significant enough. However, we can observe a tendency leaning towards positive CATE, i.e. that customers are likely to buy due to our e-mail campaign. But from the perspective of a marketing decision-maker, we would probably need to increase the size of our samples to make a profound decision on whether it is really pays off to target potential customers with e-mail campaigns.
In contrast, the results of the CEVAE indicates to rather not send e-mails to potential customers, since we only get negative CATE. However, the following gain plot shows that this result of the CEVAE is doubtable.
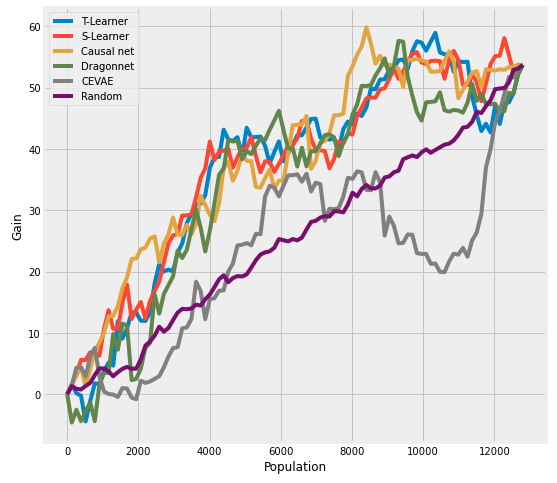
The reason why the random line is curved is that the inbuilt function plot from causalml does not draw an artificial line with a constant slope, rather, it samples from a uniform distribution within the range of 0 and 1. Because we do not have the true treatment effect \(\tau\), the estimated one is calculated as the cumulative difference between the mean outcomes of the treatment and control groups in each population. Due to the stochasity of samples from uniform distribution, we assume that it cannot be ensured that the gain line from the random model is straight anymore. Also, this conforms to the situation in reality. Compared to some examples from synthetic data, a curved random line is more pursuable in our case using data in reality.
For small or fairly large sample size, the Qini curves of the Dragonnet and T-learner have negative gains compared to the random, indicating that they require mediocre size of data for better performance. But the Qini curve of Causal Net shows a relatively stable performance regardless of the sample size. However, the Qini curve from CEVAE is unpersuasive, since it performs even worse than the random. We assume that it is because we do not tune the model and find a better parameter pool. Except for that, all of the other three models have higher AUUC than random model.
The following table consists of the metrics AUUC and Qini score for each method, which are suitable metrics to evaluate uplift models.
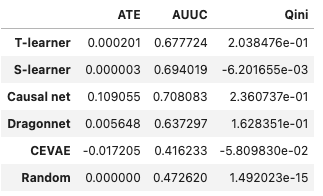
According to this table, ATE from Causal Net is highest, which is a strong support to the e-mail strategy. But the baseline model and Dragonnet tend to tell us that e-mail strategy might be meaningless, taking the cost of the strategy into account, because ATE of the two models are nearly zero. The comparison of AUUC complies to the plotting, showing Causal Net might be the most suitable model in this situation. Result from Qini indicates that using CEVAE to estimate the treatment in this case might be problematic, since it has negative Qini score and AUUC that is lower than random. Because the CEVAE has unsatifying performance in this specific setting, we do not give further interpretation of the results.
According to the AUUC and Qini, the models can be ranked from best to worse performance as in the following: Causal Net > T-learner > Dragonnet > Random > CEVAE .
Conclusion
Summary
In this notebook we explore different methods of neural networks for the estimation of treatment effects in an uplift modeling setting. It is important to carefully decide which customers should receive treatments. With uplift models we can identify customers who have no initial intention to buy, but can be persuaded due to a marketing activity (e.g. e-mail campaign). We apply and compare the performance of the Causal Net, Dragonnet and CEVAE methods while using the T-learner as our baseline model. For this we use the data of an e-mail marketing campaign provided by Hillstrom (2008). To achieve better predicting performance, we tune the hyperparameters of each neural network and the baseline model.
Both the T-learner and the Causal Net estimate the response and non-response of treatment. While the T-learner utilizes the two-model approach (i.e. one response model for treatment and another one for control), the Causal Net estimates the probability of the response on the same model. The other two models, the Dragonnet and the CEVAE, are both based on the TARnet architecture. While the Dragonnet utilizes an additional output head for the propensity score in its neural network, the CEVAE estimates the treatment effect through latent variable instead of observational variables.
From the ranking of the AUUC and Qini scores, we find that the Causal Net performs at best among all models, followed by the T-learner and the Dragonnet. Again, these results are based on the output of the sensitive analysis and tuning of the hyperparameters, except for the CEVAE , which shows the worst model performance without being tuned.
The sensitivity analysis shows that different parameter pools significantly decide the performance of a model. So far there is no unified way to realize auto-tuning, it is possible to write a tuning package concerning all current methods in the context of estimation of treatment effect. The Causal Net method is the first successful attempt to provide valid inference after using deep learning metods for first-step estimation, and achieves new rates of convergence and novel bounds for deep feedforward neural nets. Via this method we get a high AUUC score and Qini score with a reasonble estimated ATE. The training of the model is quick and the distribution of ITE is reasonable. Because it is the starting point for constructing deep learning implementations of two-estmators in several contexts, there is still space to improve this algorithm, e.g. taking cost analysis into account (Zou et al., 2020). As for the Dragonnet, we achieve a comparatively lower AUUC score and close-to-zero ATE. The Dragonnet is supposed to predict the outcome from only information relevant to treatment, and therefore, has worse performance as a predictor for the outcome, but better performance as an estimator. Again, this is due to the strong incooperation of the propensity score that leads the neural network to extract information that are relevant to predict treatment assignment. The tuning process really improves the Dragonnet’s performance significantly. The outcome of the Dragonnet model is sensitive to parameter setting, but there is no clear pattern in the result of tuning. The CEVAE could perform better if we successfully tune the model without consideration of running time limit.
Discussion and Outlook
During our project we face some limitations. Firstly, we did not handle the imbalance of the conversion in a sophisticated manner, which could be the reason why we get close-to-zero ATE. Combining the mens and womens e-mail treatment assignments is a more simpler approach. One could for example use undersampling or oversampling techniques or create synthetic data to handle the imbalance. The difficulty in Causal Net is to choose a suitable number of layers, number of neurons in each layer and the dropout rate per layer. The bad combination will cause unreasonable ATE and thus the choice of parameters is vital. A difficulty that we face with the Dragonnet is to work with a suitable sample size to have reasonable model performance. Similar to the Causal Net it is crucial for the Dragonnet to set the hyperparameters in a way to obtain reasonable results.
Another limitation that we faced is the relatively high running time of the CEVAE model.
Our project leaves some room for improvements. At first, we did not manage to reproduce a straight diagonal for the random targeting in the Gain chart. To conform to other literatures whose random line tends to be straight, it is possible to change the inbuilt function of plot in causalml, but it is also unnecessary, because a curved random line is more realistic as the stochastics in reality always exists. In future one could also explore if the setups of the neural network models show a similar performnace while working with a different (perhaps much larger) dataset.
Reference
- Devriendt, F., Moldovan, D., & Verbeke, W. (2018). A literature survey and experimental evaluation of the state-of- the-art in uplift modeling: A stepping stone toward the development of prescriptive analytics. Big Data, 6(1), 13-41.
- Farajtabar, M., Lee, A., Feng, Y., Gupta, V., Dolan, P., Chandran, H., & Szummer, M. (2020). Balance regularized neural network models for causal effect estimation. arXiv preprint arXiv:2011.11199.
- Farrell, M.H. and Liang, T. and Misra, S. (2018). Deep Neural Networks for Estimation and Inference. Econometrica. 89. 181–213.
- Hillstrom, K. (2008). The MineThatData E-Mail Analytics And Data Mining Challenge. Available at: https://blog.minethatdata.com/2008/03/minethatdata-e-mail-analytics-and-data.html (Accessed: 10.05.2021)
- Kane, K., Lo, S. Y. V., & Zheng, J. (2014). Mining for the truly responsive customers and prospects using true-lift modeling: Comparison of new and existing methods. Journal of Marketing Analytics, 2(4), 218-238.
- Künzel, S. R., Sekhon, J. S., Bickel, P. J., and Yu, B. (2019). Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the national academy of sciences, 116(10), 4156-4165.
- Lai, L. Y.-T. (2006). Influential marketing: a new direct marketing strategy addressing the existence of voluntary buyers. PhD thesis, School of Computing Science-Simon Fraser University.
- Lee J.Y., Yung M., Lo P., et al. (2021). Causalml. Available at: https://github.com/uber/causalml (Accessed: 20.08.2021)
- Lo, V. S. (2002). The true lift model: a novel data mining approach to response modeling in database marketing. ACM SIGKDD Explorations Newsletter, 4(2), 78-86.
- Louizos, C., Shalit, U., Mooij, J., Sontag, D., Zemel, R., & Welling, M. (2017). Causal effect inference with deep latent-variable models. arXiv preprint arXiv:1705.08821.
- Radcliffe, N.J. (2007). Using control groups to target on predicted lift: Building and assessing uplift models. Available at: https://www.semanticscholar.org/paper/Using-control-groups-to-target-on-predicted-lift%3A-Radcliffe/147b32f3d56566c8654a9999c5477dded233328e/figure/1 (Accessed: 19.08.2021)
- Radcliffe, N. J., & Surry, P. D. (2011). Real-World Uplift Modelling with Significance-Based Uplift Trees. Portrait Technical Report, TR-2011-1.
- Ruder, S. (2016). An overview of gradient descent optimization algorithms. Available at: https://ruder.io/optimizing-gradient-descent/ (Accessed: 29.08.2021)
- Rzepakowski P. & Jaroszewicz S. (2010). Decision trees for uplift modeling. In 2010 IEEE International Conference on Data Mining, pages 441–450.
- Shi, C., Blei, D. M. & Veitch, V. (2019a). Adapting Neural Networks for the Estimation of Treatment Effects. ArXiv:1906.02120
- Shi, C., Blei, D. M. & Veitch, V. (2019b). Dragonnet. Available at: https://github.com/claudiashi57/dragonnet (Accessed: 01.06.2021)
- Shalit U., Johansson F.D., & Sontag D. (2016). “Estimating individual treatment effect: generalization bounds and algorithms”. In: arXiv e-prints arXiv:1606.03976
- Zou, W. Y., Du, S., Lee, J., & Pedersen, J. (2020). Heterogeneous Causal Learning for Effectiveness Optimization in User Marketing. ArXiv preprint, arXiv:2004.09702v1.